
Künstliche Intelligenz mit künstlichen Daten?
Spätestens seit dem „Big Data“-Hype vor etwa 10 Jahren ist bekannt, dass Daten bzw. das daraus gewonnene Wissen der Schlüssel zum Erfolg sein werden. War damals das Credo so viele Daten wie möglich zu sammeln, ist heute bekannt, dass die Qualität der Daten und deren Verknüpfung eine entscheidende Rolle zur Wissensgenerierung darstellen. Insbesondere die Methoden der Künstlichen Intelligenz erfordern eine hohe Anzahl qualitativ hochwertiger Daten bzw. Informationen, um daraus verwertbares Wissen zu erstellen.
 Quelle: © Statista
Quelle: © Statista
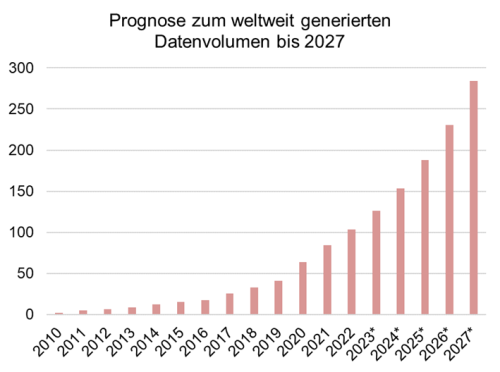
Abbildung 1: Prognose zum weltweit generierten Datenvolumen bis 2027 [1]
Das Datenvolumen, wie in Abbildung 1 dargestellt, steigt weltweit exponentiell an und ist mit 103,66 Zettabyte im Jahr 2022 riesig. Das Volumen entspricht etwa der Laufzeit eines 17.139.550.265 Jahre am Stück laufenden 4K-Films und man könnte damit die gesamte Entstehungsgeschichte der Galaxien bis zum Urknall – also 16 Milliarden Jahre – und darüber hinaus(!) dokumentieren.
Dennoch fehlt es trotz des hohen Volumens an aussagekräftigen Informationen zu diesen Daten. Speziell im Kontext der Fertigung stellen qualitativ hochwertige Daten eine Herausforderung dar. Fehlerhafte Bauteile werden im Idealfall vermieden und kommen nur selten vor, sodass ein großes Ungleichgewicht zwischen guten und schlechten Teilen herrscht. Dies macht es häufig schwierig, sehr gute Modelle für die Qualitätsvorhersage zu erstellen. Aber auch bei der vorausschauenden Wartung ist es zum Teil unmöglich, eine Maschine in den absoluten Totalschaden arbeiten zu lassen.
Mögliche Ansätze sind dedizierte Experimente, die einen Fehler oder Unregelmäßigkeiten in der Maschine oder den Rohstoffen provozieren. Diese Experimente sind allerdings teuer, da sie zum einen die laufende Wertschöpfung unterbrechen und zum anderen sehr aufwändig sind. Einen weiteren Ansatz stellen künstlich erzeugte Daten dar. Im Bereich der Fertigung und Produktion sind Simulationen, die die Realität modellhaft abbilden, nicht mehr wegzudenken. Hier können eine Vielzahl von Experimenten virtuell durchgeführt werden, die es ermöglichen, kostengünstig Daten zu erzeugen, ohne dabei aktiv in die Produktion einzugreifen.
Beispielhaft soll in diesem Beitrag die Qualitätsprüfung einer Bolzenschweißverbindung dargestellt werden. Nach DIN EN ISO 13918:2021 [2] ist ein mögliches Prüfverfahren das Anschlagen eines Bolzens mit einem Hammer. Der Klang des schwingenden Bolzens ist für erfahrene Schweißer ein Indiz für die Qualität der Schweißverbindung. In Abbildung 2 a) ist eine solche Schweißverbindung dargestellt. Beim Bolzenschweißen wird ein Stahlbolzen in einer Schweißpistole festgehalten und mit einem Strom durchflossen. Je nach Durchmesser des Bolzens entstehen hier Ströme von 1000 Ampere. Durch den Strom entsteht ein Lichtbogen, der sowohl den Grundwerkstoff als auch den Bolzen aufschmilzt. Durch ein Absenken des Bolzens in das Schmelzbad entsteht die Schweißnaht. Dabei wird der Prozess durch einen Keramikring vor äußeren Einflüssen geschützt. Zusätzlich formt der Keramikring die Schweißnaht bzw. Wulst.
Das Anschlagen des Bolzens bewirkt, dass er in seiner Eigenfrequenz schwingt. Dabei hängt diese insbesondere von den geometrischen Abmessungen der Schweißverbindung ab. Ein besonderes Merkmal ist die Wulst. Durch die hohen Ströme entsteht ein Magnetfeld, das den Lichtbogen ablenkt, sodass sich eine unsymmetrische Wulst ausbildet, die die Festigkeit der Verbindung negativ beeinflusst. Diesen Effekt nennt man Blaswirkung. Ein möglicher Ansatz zur Sicherstellung der Qualität wäre ein Verfahren, dass die Eigenfrequenzen nach dem Anschlagen erfasst und dann Aussagen zur Wulstausformung macht. Hierzu soll ein Algorithmus des maschinellen Lernens genutzt werden.
Reale Experimente, um einen ausreichenden Datensatz von >100.000 Einträgen zu erhalten, sind nicht möglich. Lediglich einige ausgewählte Experimente sollen real stattfinden und anschließend ein neues Verfahren zur Anreicherung der Daten genutzt werden.
 Quelle: © Mittelstand-Digital Zentrum Ilmenau
Quelle: © Mittelstand-Digital Zentrum Ilmenau
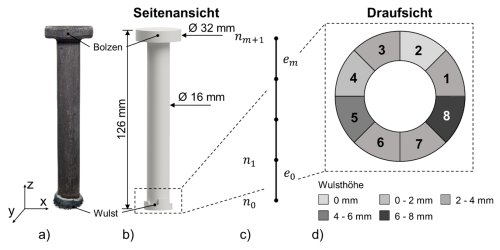
Abbildung 2: Modellierungsmethode für den Bolzen a) Real geschweißte Bolzenschweißverbindung. b).3D Modell des segmentierten Bolzens c) Modell der 1D Simulation mit Hilfe von CALFEM. d) Draufsicht auf die Schweißraupensegmente mit Abschnittsnummern und entsprechenden Raupenhöhen [2].
Die Eigenfrequenzen lassen sich mit Hilfe einer mechanischen Finiten-Elemente-Methode [3]-Simulation berechnen. Die sogenannte Modalanalyse [4] ist eine oft verwendete Simulation im Bereich des Maschinenbaus, aber auch des Bauwesens zur Bewertung des dynamischen Verhaltens von Bauteilen. Zur Berechnung der Simulation ist die reale Schweißung in ein abstrahiertes 3D-Modell überführt worden. In Abbildung 2 b) und d) ist zu erkennen, dass der Bolzen eine Zusammensetzung aus verschiedenen Zylindergrundkörpern ist. Die Wulst ist in 8 Segmente aufgeteilt worden, um asymmetrische Wülste abbilden zu können. Dabei sind die Segmenthöhen in Inkrementen [5] von 2 Millimetern variiert worden. Mit diesem Modell sind dann Berechnungen in konventionellen Simulationsprogrammen für die 3D-Simulation durchgeführt worden. Diese dauerten etwa 4 Sekunden pro Segmentvariation. Bei einem Datensatz von >100.000 entspricht das etwa 5 Tagen dauerhaftem Rechnen. Bei Variation des Bolzens im Durchmesser müssen diese Berechnungen wiederholt werden.
Die langen Berechnungszeiten sind bei der großen Variantenvielfalt im Bereich des Bolzenschweißens nicht tragbar, sodass eine weitere Abstraktion des Simulationsmodells benötigt wird. Das Open-Source-Softwarepaket CALFEM [6] ermöglicht die Erstellung einfacher 1D-Balkensimulationen, die bei der Berechnung um den Faktor 4 beschleunigt ist. Durch die Rotationssymmetrie des Bolzens lässt sich dieser auch eindimensional vernetzen. In Abbildung 2 c) ist schematisch die 1D-Vernetzung des Bolzens für die Berechnung in CALFEM dargestellt. Die Ergebnisse sind annähernd so genau, wie die Berechnungen in den konventionellen Simulationsprogrammen, sodass eine neue Methode zur Schaffung eines großen Datensatzes für das Trainieren von maschinellen Lernverfahren gegeben ist.
Tiefergehende Informationen zum neuen Simulationsansatz können in dem Paper „Investigation of a quantified sound probe for stud weld quality measurement with numerical simulation data“ von Rohe/Hildebrand/Bergmann (TU Ilmenau) [7] nachgelesen werden.
Fazit:
Der hier dargestellte Ansatz zur künstlichen Generierung von Daten bzw. die Anreicherung von vorhandenen Datensätzen mit Hilfe von Simulationen kann nicht nur auf die Fertigung bezogen werden. Auch in der Produktionsplanung können verschiedenste Experimente in einer Warenflusssimulation durchgeführt und die Daten zur Nutzung in einer Anwendung der künstlichen Intelligenz verwendet werden.
Was ist aber mit KI generierten Daten durch große Natural-Language-Modelle oder KI-Bildgeneratoren? Lässt sich hiermit die Situation ebenfalls lösen? Die Wissenschaft ist sich einig: KI wird mit KI-erzeugten Lerndaten immer schlechter [8], [9]. Somit ist der verführende Ansatz, dass sich KI selbst mit Daten versorgt, nicht möglich und die Erzeugung qualitativ hochwertiger Informationen steht weiterhin im Fokus bei der Entwicklung neuer KI-Modelle.
Ansprechpartner:
Maximilian Rohe
KI-Trainer Modellfabrik Vernetzung
Telefon: 03677/69-3856
E-Mail: rohe@kompetenzzentrum-ilmenau.de
Quellen:
[1]https://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/
[2] https://www.dinmedia.de/de/norm/din-en-iso-13918/345912787
[3] https://de.wikipedia.org/wiki/Finite-Elemente-Methode
[4] https://de.wikipedia.org/wiki/Modalanalyse
[5] https://de.wikipedia.org/wiki/Inkrement_und_Dekrement
[6] https://calfem-for-python.readthedocs.io/en/latest/index.html
[7] https://doi.org/10.22032/dbt.58853
[8] https://futurism.com/ai-trained-ai-generated-data
[9] https://www.scientificamerican.com/article/ai-generated-data-can-poison-future-ai-models/
Bildquellen
- Abbildung 1: © Statista
- Abbildung 2: © Mittelstand-Digital Zentrum Ilmenau
- Titelbild: DCStudio – MotionArray



